
Databend v0.9.0 was officially released on January 13, 2023! This release is the last major release of Databend before version 1.0, and it is also the version in which we have refactored the core code the most so far. Compared to v0.8.0, we have made more than 5,000 commits, 700+ optimizations and fixes, 4,347 file changes, and 340,000 lines of code changes in v0.9.0. Thanks to all the community partners who participated and to everyone who made Databend better!
In v0.9.0, we introduced a new type system, a new expression calculation framework, JSONB support, complete JOIN support and optimization, CBO support, a native storage format and other major feature optimizations. A lot of optimization and enhancements have also been made in terms of performance, stability, and usability.
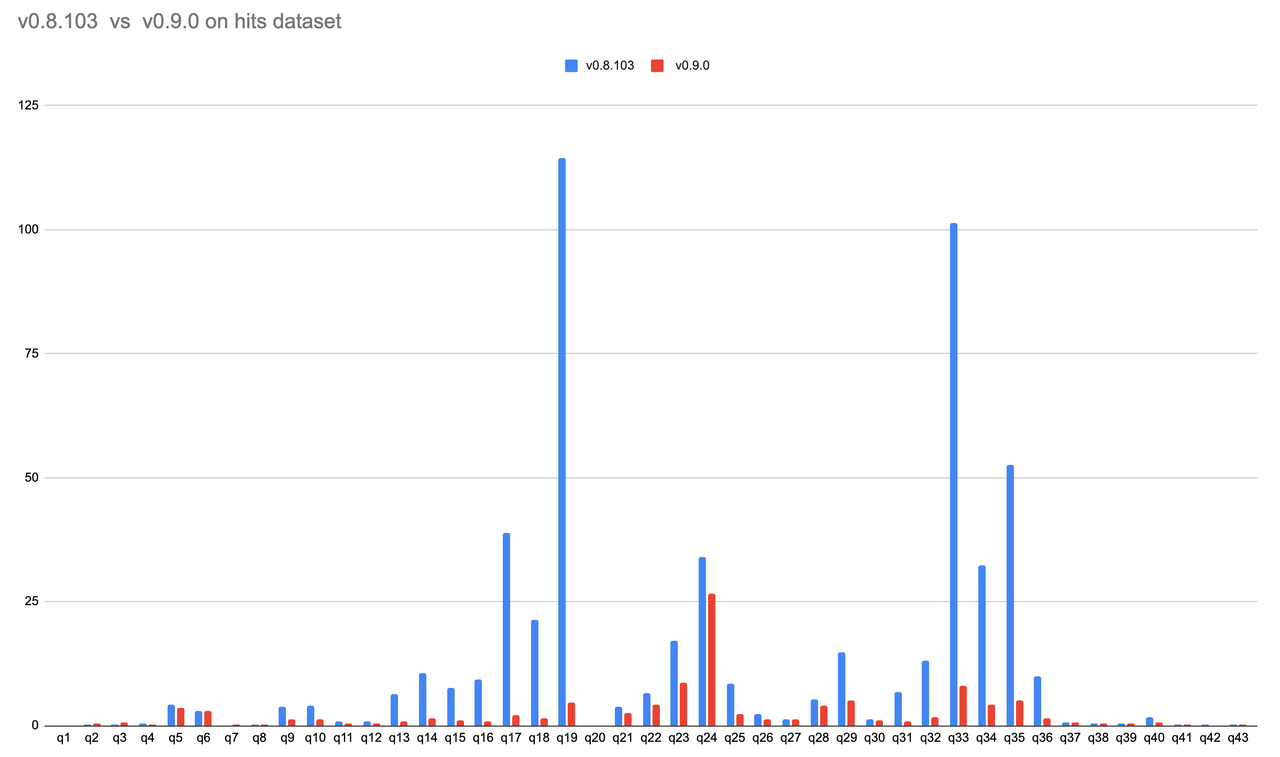
Performance comparison
In the new version, we have made a lot of optimizations in the execution engine, optimizer, and storage layer. The efficiency gets doubled in most scenarios. The following is a performance comparison between v0.8 and v0.9 benchmarking the Hits dataset with the default FUSE engine on S3:
Brand new type system
To give databend an easy-to-understand yet powerful type derivation system, we learned from the compiler internals of a number of good programming languages and then refined a subset of them for SQL. Based on the current purely static type system, we have a sophisticated type derivation mechanism that infers the execution of expressions as much as possible at the compile time of SQL, a minimalist expression function registration logic, and the implementation of generic derivation at the database type level.
On top of the new type system, modules such as constant folding, type derivation, function registration, query data trimming, etc. can benefit from the new type system.
Support for JSONB
In the new version, we implemented the Rust version of JSONB, the default JSON data type will be stored in JSONB, and it is also compatible with the old JsonText format. Based on the binary JSON format, both storage space and query performance have been significantly optimized.
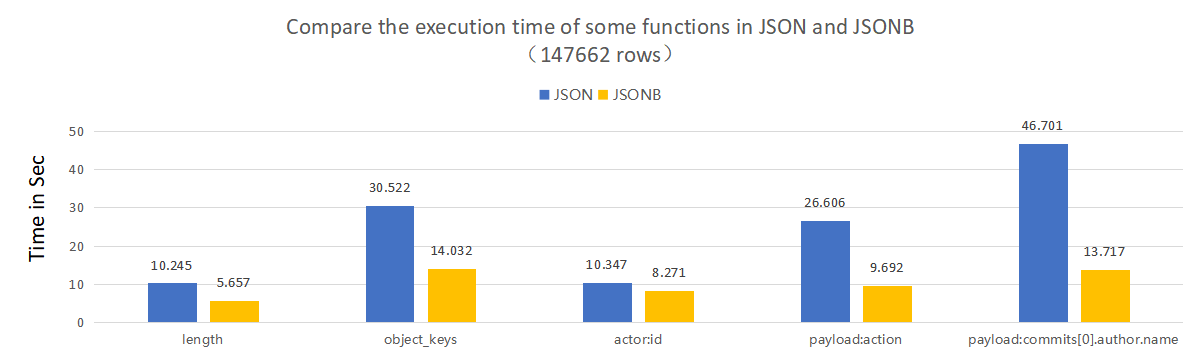
More info: https://databend.rs/doc/contributing/rfcs/json-optimization
Full support for JOINs
Full Join types are supported: inner/natural/cross/outer/semi/anti joins. In the past few months, according to the feedback from the community and online users, hash join has been deeply optimized to meet the performance requirements in most scenarios.
Support for CBO
We have added the statistical calculation logic of NDV in the statistical information, and users can now generate statistical information tables through the "Analyze" command similar to presto. JOINs can use the existing statistical information to optimize the logical plan based on cost. After the subsequent CBO support is improved, we will update the query performance data comparison of TPCH 100G data.
Native Storage Format
Databend supports Git-Like's Fuse engine. Based on this engine, we can quickly go back to a certain historical point in time to query, and realize "time travel" inside the database. Inside the Fuse engine, we also support a new Storage Format besides Parquet --- strawboat: https://github.com/sundy-li/strawboat.
Strawboat is based on Arrow's native storage format. Based on it, we can read data more efficiently than Parquet. In the hits dataset, the full table scan native format can be 2-3 times faster. In the hits data set, a very considerable improvement has been achieved in the local deployment scenario, and we will improve the performance comparison in clickbench later.
Efficient bloom filter filtering
In the new version, we introduced the xor filter to calculate and store the bloom filter for each column. Compared with the previous version, the new bloom filter has improved a lot in import query performance and occupied space. See https://databend.rs/blog/xor-filter
Designing and open-sourcing serverless DataSharing protocol
In the new version we created a zero-trust data sharing solution among multi-tenants based on object storage presign short-term access token. In the case of consistent basic performance, aws lambda will be used to implement data sharing in a serverless manner.
Stage
We implemented UserStage in the new version, similar to the home directory of linux: COPY INTO my_table FROM @~;
- Stage's data import supports meta storage status, which means we can always save and import new files from stage.
- Support exporting multiple files in different formats from Stage.
- Importing tables from Stage supports parallelization.
Other improvements
The new release also includes these improvements:
- Read_parquet of duckdb supports reading local parquet files directly without importing
- Commonly used function performance optimization, commonly used GEO function support
- Distinct performance optimization
- Adaptive String HashTable
- SQLancer integration
- Parquet reading acceleration
- The previous python version sqllogictest was rewritten to use Rust
- NDJSON and JSON output format support
- ALTER TABLE supports recluster
- Support hyperloglog update and delete: https://db.in.tum.de/~freitag/papers/p23-freitag-cidr19.pdf
Download v0.9.0
If you are interested in Databend v0.9.0, go to https://github.com/datafuselabs/databend/releases/tag/v0.9.0-nightly to view all changelogs or download the release.
If you are using an old version of Databend, you can directly upgrade to the new version. For the upgrade process, please refer to: https://databend.rs/doc/operations/upgrade
Feedback
If you need any help when working with the new release, submit an issue on Github Issue. GitHub: https://github.com/datafuselabs/databend/