Sccache is a ccache-like project started by the Mozilla team, supporting C/CPP, Rust and other languages, and storing caches locally or in a cloud storage backend. In v0.3.3, Sccache added native support for the Github Action Cache Service; in the subsequent v0.4.0-pre.6, the community has continued to improve this functionality, and it is now ready for use in the production CI.

I recently added sccache to the PyO3/maturin CI for testing, and found it to have the following advantages
- Easy deployment configuration: No need to specify
shared key, no need to worry about GHA's internal cache-from/cache-to logic, just configureSCCACHE_GHA_ENABLED: "true". - Multi-language support: sccache supports caching different compilers for C/CPP, Rust and nvcc at the same time.
- Faster in most scenarios: sccache caches the compilation product, no need to load the entire cache in advance, and no need to upload the cached content after the build is complete.
- Concurrent job friendly: sccache can share caches between multiple concurrent jobs/workflows, no need to wait until the end of the build.
- No cache conflicts: sccache performs hash calculations on each build product input (parameters, environment variables, files, etc.) to build a global conflict-free cache without cache conflicts and without the need to specify additional different cache keys.
- No vendor lock-in: sccache is built on [opendal] (https://github.com/datafuselabs/opendal) and naturally supports a variety of different storage services, allowing seamless migration to s3/gcs/azlob etc. in future CI evolutions without relying on GHA cache services.
- Actively maintained: sccache is currently actively maintained by me, you can submit feedback directly if you encounter problems using it.
The following are the results of the maturin project tests.
| Cases | Sccache vs rust-cache (2nd) | Sccache vs rust-cache (3rd) |
|---|---|---|
| Test (ubuntu-latest, 3.7) | 59.72% | -1.68% |
| Test (ubuntu-latest, 3.8) | -4.70% | -8.22% |
| Test (ubuntu-latest, 3.9) | 30.72% | 10.81% |
| Test (ubuntu-latest, 3.10) | 1.03% | 12.15% |
| Test (ubuntu-latest, 3.11) | -10.16% | -29.35% |
| Test (ubuntu-latest, pypy3.8) | 18.34% | -3.84% |
| Test (ubuntu-latest, pypy3.9) | 5.13% | 22.90% |
| Test (macos-latest, 3.7) | 11.87% | 5.65% |
| Test (macos-latest, 3.8) | -7.82% | -13.65% |
| Test (macos-latest, 3.9) | -17.98% | -45.20% |
| Test (macos-latest, 3.10) | -13.20% | -15.38% |
| Test (macos-latest, 3.11) | -17.44% | -29.55% |
| Test (macos-latest, pypy3.8) | 14.83% | -23.32% |
| Test (macos-latest, pypy3.9) | -28.03% | -38.56% |
| Test (windows-latest, 3.7) | 30.08% | 24.22% |
| Test (windows-latest, 3.8) | 35.11% | 41.14% |
| Test (windows-latest, 3.9) | 9.24% | -5.28% |
| Test (windows-latest, 3.10) | -8.56% | -15.81% |
| Test (windows-latest, 3.11) | -1.39% | -36.49% |
| Test (windows-latest, 3.8) | -19.99% | -35.54% |
| Test (windows-latest, 3.9) | 18.95% | -8.55% |
The table compares the difference between a second/third run with sccache and a run with rust-cache, with bolded plural entries indicating that sccache is faster than rust-cache. As you can see, as the cache hit rate increases, sccache achieves a maximum improvement of almost 50% over rust-cache.
Give sccache a try, and if you don't like it, go to issues for feedback, and feel free to contribute!
In the next section I will first describe the internal API of the Github Action Cache Service and how it works, and then compare the differences between the rust-cache / sccache implementations to show why sccache is better / faster.
Github Action Cache Service Principle
The Github Action Cache Service is essentially an immutable storage service that supports prefix queries and provides the following non-public API.
Query Cache
GET /cache?keys=abc,ab,a&version=v1
keys: Specify a comma-separated set of query keys, the result will be the latest key with the same version prefix matchversion:Specify the namespace used by the cache key
Reserve Cache
POST /caches
- inputs:
{key: <cache_key>, version: <cache_version>} - outputs:
{cache_id: <cache_id>}
After each set of (key, version) has been reserved, all subsequent requests with the same key & version will return an already exists error, meaning that the cache cannot be overwritten. A successful request will return a numeric cache_id, which will be used for subsequent uploads and cache creation.
Upload Cache
PATCH /caches/[cache_id]
Upload specific cache content, using Content-Range to mark the cache location for this upload.
Create Cache
POST /caches/[cache_id]
This API can be used to create a cache after all the cached content has been created. The cache will only be queried after a successful response from this API.
rust-cache implementation
On top of this internal API (which is reasonably suspected to be provided by Azure DevOps services), Github provides actions/cache for users to use, and rust-cache is based on the @actions/cache implementation.
rust-cache calculates a cache key based on the github job_id, rustc version, environment variables, Cargo.lock, etc., and then packages ~/.cargo and . /target into one package and upload it. If the cache hits, it will be loaded locally and unpacked, if the cache misses, the cache will be uploaded in the post action.
The advantage of rust-cache is that the GHA Cache API is only called once for the whole process and the rate limit is rarely triggered.
sccache implementation
The GHA implementation of sccache is completely file based.
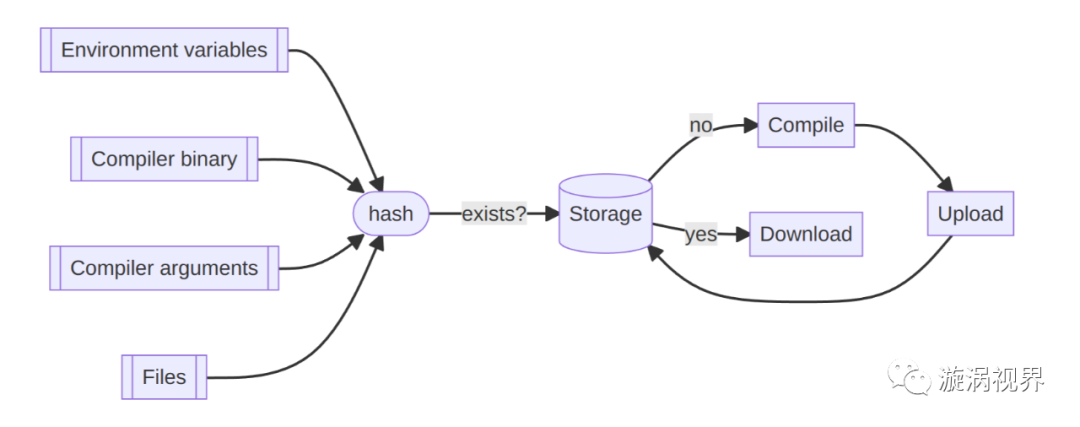
sccache calculates a hash as a cache key based on the environment variables, binary, compilation parameters, input files, etc. passed during each rustc call, and loads the file directly from the storage service if it exists, skipping this compilation operation, otherwise it compiles and writes the result to the storage service. This means that
- sccache does not have to deal with cache conflicts caused by different inputs, and can use an always unique hash as the cache key.
- sccache can download the required cache at rustc compile time, without having to load the entire contents beforehand, or upload them all after the job has finished.
- Sccache's cache loading logic is not heavily dependent on Cargo.lock itself, so the cache can be reused even if a large number of dependencies change.
- sccache can reuse the cache between concurrent jobs, as they all share the same non-conflicting memory space.
In addition, sccache can be used for compilation caching of languages such as c/cpp, and if compilers such as gcc/clang are also used in the project, the cache can be shared with a simple configuration.
To help users make better use of Sccache in Github Action, we have developed sccache-action. However, my PR is not currently merged and can be used first with my fork:
- name: Sccache Setup
# Just for test, come back to upstream after released
uses: Xuanwo/sccache-action@c94e27bef21ab3fb4a5152c8a878c53262b4abb0
with:
version: "v0.4.0-pre.6"
Next, only two environment variables need to be configured.
env:
SCCACHE_GHA_ENABLED: "true"
RUSTC_WRAPPER: "sccache"
At the end of each Job, sccache-action outputs the usage of this Cache.
/opt/hostedtoolcache/sccache/0.4.0-pre.6/x64/sccache --show-stats
Compile requests 1887
Compile requests executed 1035
Cache hits 836
Cache hits (C/C++) 22
Cache hits (Rust) 814
Cache misses 189
Cache misses (Rust) 189
Cache timeouts 0
Cache read errors 0
Forced recaches 0
Cache write errors 0
Compilation failures 10
Cache errors 0
Non-cacheable compilations 0
Non-cacheable calls 852
Non-compilation calls 0
Unsupported compiler calls 0
Average cache write 0.051 s
Average compiler 1.132 s
Average cache read hit 0.000 s
Failed distributed compilations 0
Non-cacheable reasons:
crate-type 521
- 320
unknown source language 11
Cache location ghac, name: sccache-v0.4.0-pre.6, prefix: /sccache/
Users can use this information to adjust their strategy for using sccache.
Conclusion
Sccache uses GHA Cache in a new way to accelerate the compilation of Rust projects, with the following advantages over existing solutions
- Easy deployment and configuration
- Multiple language support
- Faster in most scenarios
- Concurrent task friendly
- No cache conflicts
- No vendor lock-in
- Active maintenance
Feel free to try and use Sccache in your own projects!






![dependabot[bot]](https://avatars.githubusercontent.com/in/29110?v=4&s=117)





![mergify[bot]](https://avatars.githubusercontent.com/in/10562?v=4&s=117)